
Asymptotics of Gaussian Tails
The Gaussian probability distribution is given by the expression
(1)
![P[x,\bar{x};\sigma] = \frac{1}{\sigma \sqrt{2\pi}} \exp\left( -\frac{1}{2} \left( \frac{x-\bar{x}}{\sigma} \right)^2 \right) ,](https://s0.wp.com/latex.php?latex=P%5Bx%2C%5Cbar%7Bx%7D%3B%5Csigma%5D+%3D+%5Cfrac%7B1%7D%7B%5Csigma+%5Csqrt%7B2%5Cpi%7D%7D+%5Cexp%5Cleft%28+-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%29+%2C&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where ![P[x,\bar{x};\sigma] dx](https://s0.wp.com/latex.php?latex=P%5Bx%2C%5Cbar%7Bx%7D%3B%5Csigma%5D+dx&bg=ffffff&fg=1a1a1a&s=0&c=20201002)



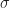
Suppose we wish to compute what fraction ![f[x_\star]](https://s0.wp.com/latex.php?latex=f%5Bx_%5Cstar%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![P[x,\bar{x};\sigma]](https://s0.wp.com/latex.php?latex=P%5Bx%2C%5Cbar%7Bx%7D%3B%5Csigma%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

(2)
![f[x_\star] = \int_{x_\star}^\infty P[x,\bar{x};\sigma] dx .](https://s0.wp.com/latex.php?latex=f%5Bx_%5Cstar%5D+%3D+%5Cint_%7Bx_%5Cstar%7D%5E%5Cinfty+P%5Bx%2C%5Cbar%7Bx%7D%3B%5Csigma%5D+dx+.+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
When this threshold is very large, namely 
(3)
![f[x_\star] = \frac{1}{\sigma \sqrt{2\pi}} \int_{x_\star}^\infty \frac{\partial_x \exp\left[-\frac{1}{2} \left( \frac{x-\bar{x}}{\sigma} \right)^2 \right]}{-(x-\bar{x})/\sigma^2} dx .](https://s0.wp.com/latex.php?latex=f%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B1%7D%7B%5Csigma+%5Csqrt%7B2%5Cpi%7D%7D+%5Cint_%7Bx_%5Cstar%7D%5E%5Cinfty+%5Cfrac%7B%5Cpartial_x+%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B-%28x-%5Cbar%7Bx%7D%29%2F%5Csigma%5E2%7D+dx+.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
After one integration-by-parts,
(3′)
![f[x_\star] = \frac{1}{\sigma \sqrt{2\pi}} \left( \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}}{\sigma} \right)^2 \right]}{(x_\star-\bar{x})/\sigma^2} - \int_{x_\star}^\infty \frac{dx}{(x-\bar{x})^2/\sigma^2} \frac{\partial_x \exp\left[-\frac{1}{2} \left( \frac{x-\bar{x}}{\sigma} \right)^2 \right]}{-(x-\bar{x})/\sigma^2} \right).](https://s0.wp.com/latex.php?latex=f%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B1%7D%7B%5Csigma+%5Csqrt%7B2%5Cpi%7D%7D+%5Cleft%28+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma%5E2%7D+-+%5Cint_%7Bx_%5Cstar%7D%5E%5Cinfty+%5Cfrac%7Bdx%7D%7B%28x-%5Cbar%7Bx%7D%29%5E2%2F%5Csigma%5E2%7D+%5Cfrac%7B%5Cpartial_x+%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B-%28x-%5Cbar%7Bx%7D%29%2F%5Csigma%5E2%7D+%5Cright%29.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
After 
(3”)
![f[x_\star] = \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}}{\sigma} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x})/\sigma} \left( 1 + \frac{A_2}{(x_\star - \bar{x})^2/\sigma^2} + \dots + \frac{A_{2(n-1)}}{(x_\star - \bar{x})^{2n}/\sigma^{2n}} \right) + B_{2n} \int_{x_\star}^\infty \frac{\exp\left[-\frac{1}{2} \left( \frac{x-\bar{x}}{\sigma} \right)^2 \right]}{(x-\bar{x})^{2n}/\sigma^{2n-1}} dx ,](https://s0.wp.com/latex.php?latex=f%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma%7D+%5Cleft%28+1+%2B+%5Cfrac%7BA_2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%2F%5Csigma%5E2%7D+%2B+%5Cdots+%2B+%5Cfrac%7BA_%7B2%28n-1%29%7D%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E%7B2n%7D%2F%5Csigma%5E%7B2n%7D%7D+%5Cright%29+%2B+B_%7B2n%7D+%5Cint_%7Bx_%5Cstar%7D%5E%5Cinfty++%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%28x-%5Cbar%7Bx%7D%29%5E%7B2n%7D%2F%5Csigma%5E%7B2n-1%7D%7D+dx+%2C+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
for some numerical constants 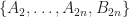
(4)
![f[x_\star] = \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}}{\sigma} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x})/\sigma} \left( 1 - \frac{\sigma^2}{(x_\star - \bar{x})^2} + \mathcal{O}\left( (x_\star-\bar{x})^{-4} \right) \right).](https://s0.wp.com/latex.php?latex=f%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma%7D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%7D+%2B+%5Cmathcal%7BO%7D%5Cleft%28+%28x_%5Cstar-%5Cbar%7Bx%7D%29%5E%7B-4%7D+%5Cright%29++%5Cright%29.+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We infer from eq. (3”) that a power series in 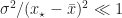
![\left\vert \frac{1}{\sqrt{2\pi}} \int_{x_\star}^\infty \frac{\exp\left[-\frac{1}{2} \left( \frac{x-\bar{x}}{\sigma} \right)^2 \right]}{(x-\bar{x})^{2n}/\sigma^{2n-1}} dx \right\vert \leq \left\vert \frac{\sigma^{2n}}{(x_\star - \bar{x})^{2n}} \right\vert f[x_\star] .](https://s0.wp.com/latex.php?latex=%5Cleft%5Cvert+%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%7D+%5Cint_%7Bx_%5Cstar%7D%5E%5Cinfty+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%28x-%5Cbar%7Bx%7D%29%5E%7B2n%7D%2F%5Csigma%5E%7B2n-1%7D%7D+dx+%5Cright%5Cvert+%5Cleq+%5Cleft%5Cvert+%5Cfrac%7B%5Csigma%5E%7B2n%7D%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E%7B2n%7D%7D+%5Cright%5Cvert+f%5Bx_%5Cstar%5D+.++&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Dividing the 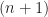



![\lim_{(x_\star-\bar{x})/\sigma \to \infty} \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}}{\sigma} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x})/\sigma} \left( 1 + \frac{A_2}{(x_\star - \bar{x})^2/\sigma^2} + \dots + \frac{A_{2n}}{(x_\star - \bar{x})^{2n}/\sigma^{2n}} \right) \to f[x_\star] .](https://s0.wp.com/latex.php?latex=%5Clim_%7B%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma+%5Cto+%5Cinfty%7D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma%7D+%5Cleft%28+1+%2B+%5Cfrac%7BA_2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%2F%5Csigma%5E2%7D+%2B+%5Cdots+%2B+%5Cfrac%7BA_%7B2n%7D%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E%7B2n%7D%2F%5Csigma%5E%7B2n%7D%7D+%5Cright%29+%5Cto+f%5Bx_%5Cstar%5D+.+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Comparing Gaussian Tails
A key observation that I wish to highlight in this post is that, when comparing the tail ends of two different Gaussian distributions, the higher the threshold
Different Means, Same Variance
Let group 


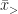
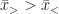
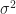
- What fraction
of
- What fraction
of
- If
denotes the total population of
that of
of the total number from
From eq. (4), we may answer the questions, respectively as
![f_A[x_\star] = \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}_<}{\sigma} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x}_<)/\sigma} \left( 1 - \frac{\sigma^2}{(x_\star - \bar{x}_<)^2} + \mathcal{O}\left( (x_\star-\bar{x}_<)^{-4} \right) \right) ;](https://s0.wp.com/latex.php?latex=f_A%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D_%3C%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D_%3C%29%2F%5Csigma%7D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D_%3C%29%5E2%7D+%2B+%5Cmathcal%7BO%7D%5Cleft%28+%28x_%5Cstar-%5Cbar%7Bx%7D_%3C%29%5E%7B-4%7D+%5Cright%29+%5Cright%29+%3B+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![f_B[x_\star] = \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}_>}{\sigma} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x}_>)/\sigma} \left( 1 - \frac{\sigma^2}{(x_\star - \bar{x}_>)^2} + \mathcal{O}\left( (x_\star-\bar{x}_>)^{-4} \right) \right) ;](https://s0.wp.com/latex.php?latex=f_B%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D_%3E%7D%7B%5Csigma%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D_%3E%29%2F%5Csigma%7D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D_%3E%29%5E2%7D+%2B+%5Cmathcal%7BO%7D%5Cleft%28+%28x_%5Cstar-%5Cbar%7Bx%7D_%3E%29%5E%7B-4%7D+%5Cright%29+%5Cright%29+%3B+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and
(5)
![R_\sigma = \frac{N_A}{N_B} \left( \frac{x_\star-\bar{x}_>}{x_\star-\bar{x}_<} \right) \exp\left[-\frac{1}{2 \sigma^2}\left( 2 x_\star - \bar{x}_> - \bar{x}_< \right)(\bar{x}_> - \bar{x}_<) \right] \left( 1 - \frac{\sigma^2}{(x_\star - \bar{x}_<)^2} + \frac{\sigma^2}{(x_\star - \bar{x}_>)^2} + \dots \right) .](https://s0.wp.com/latex.php?latex=R_%5Csigma+%3D+%5Cfrac%7BN_A%7D%7BN_B%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D_%3E%7D%7Bx_%5Cstar-%5Cbar%7Bx%7D_%3C%7D+%5Cright%29+%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2+%5Csigma%5E2%7D%5Cleft%28+2+x_%5Cstar+-+%5Cbar%7Bx%7D_%3E+-+%5Cbar%7Bx%7D_%3C+%5Cright%29%28%5Cbar%7Bx%7D_%3E+-+%5Cbar%7Bx%7D_%3C%29+%5Cright%5D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D_%3C%29%5E2%7D+%2B+%5Cfrac%7B%5Csigma%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D_%3E%29%5E2%7D+%2B+%5Cdots+%5Cright%29+.+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Same Mean, Different Variances
Let group 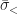
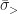

- What fraction
- What fraction
- If
of the total number from
From eq. (4), we may answer the questions, respectively as
![f_A[x_\star] = \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}}{\sigma_<} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x})/\sigma_<} \left( 1 - \frac{\sigma_<^2}{(x_\star - \bar{x})^2} + \mathcal{O}\left( (x_\star-\bar{x})^{-4} \right) \right) ;](https://s0.wp.com/latex.php?latex=f_A%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D%7D%7B%5Csigma_%3C%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma_%3C%7D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma_%3C%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%7D+%2B+%5Cmathcal%7BO%7D%5Cleft%28+%28x_%5Cstar-%5Cbar%7Bx%7D%29%5E%7B-4%7D+%5Cright%29+%5Cright%29+%3B+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![f_B[x_\star] = \frac{\exp\left[-\frac{1}{2} \left( \frac{x_\star-\bar{x}}{\sigma_>} \right)^2 \right]}{\sqrt{2\pi} \cdot (x_\star-\bar{x})/\sigma_<} \left( 1 - \frac{\sigma_>^2}{(x_\star - \bar{x})^2} + \mathcal{O}\left( (x_\star-\bar{x})^{-4} \right) \right) ;](https://s0.wp.com/latex.php?latex=f_B%5Bx_%5Cstar%5D+%3D+%5Cfrac%7B%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D+%5Cleft%28+%5Cfrac%7Bx_%5Cstar-%5Cbar%7Bx%7D%7D%7B%5Csigma_%3E%7D+%5Cright%29%5E2+%5Cright%5D%7D%7B%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%28x_%5Cstar-%5Cbar%7Bx%7D%29%2F%5Csigma_%3C%7D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma_%3E%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%7D+%2B+%5Cmathcal%7BO%7D%5Cleft%28+%28x_%5Cstar-%5Cbar%7Bx%7D%29%5E%7B-4%7D+%5Cright%29+%5Cright%29+%3B+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
and
(6)
![R_{\bar{x}} = \frac{N_A}{N_B} \cdot \frac{\sigma_<}{\sigma_>} \cdot \exp\left[-\frac{1}{2 \sigma_>^2 \sigma_<^2} \left( x_\star - \bar{x} \right)^2 \left( \sigma_>^2 - \sigma_<^2 \right) \right] \left( 1 - \frac{\sigma_<^2}{(x_\star - \bar{x})^2} + \frac{\sigma_>^2}{(x_\star - \bar{x})^2} + \dots \right) .](https://s0.wp.com/latex.php?latex=R_%7B%5Cbar%7Bx%7D%7D+%3D+%5Cfrac%7BN_A%7D%7BN_B%7D+%5Ccdot+%5Cfrac%7B%5Csigma_%3C%7D%7B%5Csigma_%3E%7D+%5Ccdot+%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2+%5Csigma_%3E%5E2+%5Csigma_%3C%5E2%7D+%5Cleft%28+x_%5Cstar+-+%5Cbar%7Bx%7D+%5Cright%29%5E2+%5Cleft%28+%5Csigma_%3E%5E2+-+%5Csigma_%3C%5E2+%5Cright%29+%5Cright%5D+%5Cleft%28+1+-+%5Cfrac%7B%5Csigma_%3C%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%7D+%2B+%5Cfrac%7B%5Csigma_%3E%5E2%7D%7B%28x_%5Cstar+-+%5Cbar%7Bx%7D%29%5E2%7D+%2B+%5Cdots+%5Cright%29+.+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Very Taboo Topic: IQ of Different Human Groups
Even though the tail ends of a Gaussian distributed population comprises an exponentially small fraction of the total population, they correspond to extreme characteristics — for e.g., the fastest runners, most brilliant geniuses, etc. — and can therefore assert an outsized impact. For example, it is reasonable to expect, progress in fundamental science has been driven largely by people occupying the upper tail end of the cognitive spectrum. This topic has become extremely taboo in recent times due to the politically correct Far Left Fundamentalism err I meant the Holy Church of Diversity, Inclusion and Equity that has deeply permeated Western Academia.
If human intelligence is well reflected by IQ scores, and if IQ scores of a given human group are well modeled by a Gaussian distribution, then my understanding of the psychology literature indicates:
- There are differences in average intelligence levels of distinct human groups; for e.g., between Blacks and Ashkenazi Jews in the US. In each group, there will of course be extremely dull and very bright folks; but the means are not the same. In particular, the Black average IQ is lower than the White average IQ; whereas Ashkenazi Jews have an average IQ that is among the highest across human groups. In other words, Ashkenazi Jews are on average more intelligent than Blacks.
- Males and females, on average, have roughly the same intelligence. However, the spread is larger for males than for females — this is known as greater male variability: more males than females are extremely clever; and more males than females are extremely dumb.
The asymptotic analysis we performed above can be applied to these situations, and I believe is important for understanding why for instance we see far more American Jews than Blacks winning Nobel Prizes in Physics or holding distinguished Chair Professorships in Mathematics at Princeton / Harvard / UC Berkeley / etc. For similar reasons, we should expect far more men than women to acquire the most coveted leadership positions in STEM fields. The latter is exacerbated by the also well documented fact that, on average, women are less interested in ‘things’ than men.
More specifically, if we — as a crude approximation — suppose the standard deviation 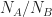

Personal Thoughts
The above are the facts as I understand them — I think it is important to distinguish between the Science and the Ethics; because the former deals strictly with reality as it is, whereas the latter deals with subjective human values. To entangle them will only lead to the corruption of our grasp on reality itself.
In my opinion, the nobility of equal dignity for all should not be predicated upon the sameness of humans. That is, I do believe in treating our fellow humans equally, but not because they are all clones of one another. In particular, equal opportunity means: we should allow all to compete equally, so that the best ideas and the most competent folks would win. Trying to enforce equal outcomes — same number of males and females in STEM fields, for e.g. — will, I am afraid, only lead to disaster. On the other hand, just because we are less talented in one or more areas does not mean we cannot find personal fulfillment and self-worth in life through other means. Growing up with a life-long disability, I have learned this quite early on.
I do worry significantly about where the free Western societies of our human civilization are moving. Even the scientific communities are unwilling or unable to come to terms with the reality of human group differences. This does not bode well for our long term collective scientific integrity.
At the end of the investigation into the Space Shuttle Challenger disaster, theoretical physicist Richard Feynman gave the following warning:
For a successful technology, reality must take precedence over public relations, for nature cannot be fooled.
Richard P. Feynman
If I may paraphrase the great Feynman for our current climate:
For a successful Democracy that values Science, Reality must take precedence over Political Correctness, for Nature cannot be fooled.

I have for the longest stressed the importance of variance as much as the absolute average sample measurement. Consider two sample groups, with precisely identical average IQ. I would contend that the group with greater variance will produce a greater percentage of prominent outliers, the high-achieving intellectuals who make significant and sometimes revolutionary contributions to the gamut of human knowledge and understanding. One could even imagine a scenario where a group whose average IQ was actually lower than another’s could produce more geniuses, if its variance in IQ were sufficiently greater than the latter’s.
You can pull with a string, but you can’t push. Frequently, it is individuals of high intellectual ability who advance mathematical and scientific understanding. Their unintelligent counterparts however, reflected symmetrically across the Gaussian curve, do not exert an opposite effect on those fields; They do not decrease collective human knowledge. In fact, they have no effect whatsoever, as does the vast majority of the average folks lingering about the center of the bell curve. We’re all just pushing on a string.
The societal impact of the average IQ is undoubtedly salient. IQ has been shown to correlate with many social metrics and statistical outcomes that we consider pertinent to our personal and societal quality of life, notably, crime and poverty. The impact of IQ upon academia, however, is not a classical system. We can’t just naively add up vectors to arrive at a net result. Instead, it’s much more comparable to a quirky quantum system, wherein genetic probabilistic models occasionally tunnel individual souls past some high IQ threshold, beyond which conspicuous academic academic contributions are likely to be achieved. The vast majority of us will only sustain the status quo, without innovating much.
This is what’s meant by the statement (I don’t know to whom attribution is owed), “A million persons have drowned in lakes with an average depth of three feet”. It’s ultimately just the deep parts that matter.
LikeLike
Regarding your “not a classical system” remark — what is different about academia that makes the impact of IQ different from its impact in the societal case? I’d think the former is in fact much more directly related to cognitive ability?
LikeLike